
Несмотря на то, что современные графические процессоры в основном рассчитаны на вычисления с пониженной точностью, оптимальные для задач искусственного интеллекта, операции с высокой точностью FP64 остаются «крайне значимыми» для «Миссии Генезис» и её цели — ускорить научный прогресс с помощью ИИ. Об этом в беседе с HPCwire заявил заместитель министра энергетики США по научной работе и инновациям Дарио Гил (Darío Gil).
«В ходе моих бесед и с [генеральным директором AMD] Лизой Су (Lisa Su), и с [генеральным директором NVIDIA] Дженсеном Хуангом (Jensen Huang) они чётко подтвердили свою приверженность поддержке формата FP64, — отметил Гил. — Для нас это имеет принципиальное значение, поскольку мы видим в этом не замену, а взаимодополняющие технологии». По его словам, для выполнения как традиционных задач моделирования и симуляции, лежащих в основе научных расчётов, так и для новых подходов на базе ИИ, критически важно наличие высокопроизводительных аппаратных решений.
Гил также подчеркнул, что оба типа вычислений будут совместно использоваться для достижения цели «Миссии Генезис» — раздвинуть границы науки и инженерии благодаря технологиям искусственного интеллекта. «Существуют высокоточные симуляционные коды, работающие на FP64. После их верификации они служат основой для создания данных, на которых обучается суррогатная модель, запускаемая затем на ИИ-суперкомпьютере, — пояснил он. — В результате вы получаете выигрыш в производительности и скорости получения результатов, часто в десятки, два десятка или даже в сотни раз».
Источник изображений: NVIDIA
Он подчеркнул, что применение моделей искусственного интеллекта способно привести к значительному росту эффективности, однако этот рост обусловлен сохранением полного рабочего цикла, включающего эксперименты, симуляции и обучение. «Разрыв этого цикла, например, утрата исходных кодов моделирования, создаёт серьёзные трудности», — пояснил Гил. «Для нас это принципиальный вопрос — не только в плане поддержки унаследованных кодов, критически важных для выполнения задач, но и для обеспечения функционирования всего ИИ-процесса. Вот почему для нас крайне важно сохранять разнообразие архитектурных решений», — добавил он.
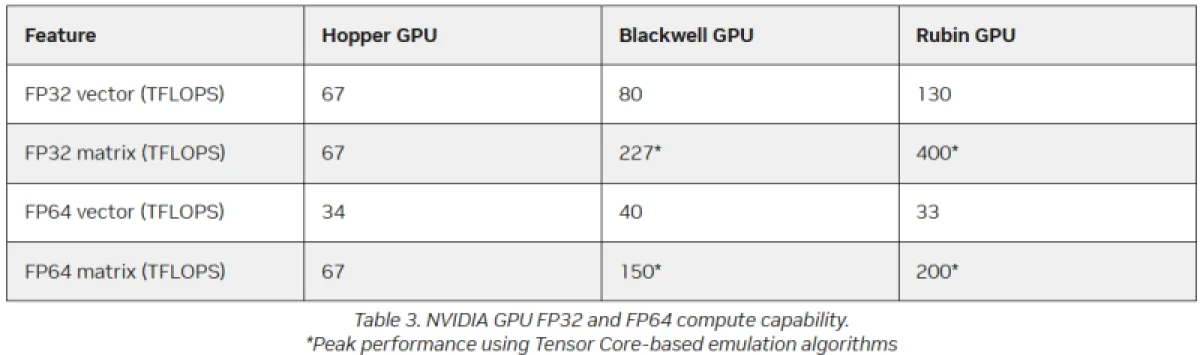
В среде специалистов по высокопроизводительным вычислениям растёт беспокойство из-за отсутствия прогресса в производительности для операций с двойной точностью (FP64) в современных графических процессорах. Например, чип NVIDIA H100, представленный в 2022 году, демонстрирует 67 Тфлопс в формате FP64 на тензорных ядрах (и 34 Тфлопс на векторных), тогда как модель B200 обеспечивает лишь 37 Тфлопс, а B300 — всего около 1,3 Тфлопс. Программная эмуляция вычислений FP64 на тензорных ядрах архитектуры Blackwell позволяет достичь «нечестных» 150 Тфлопс, а в новейшей архитектуре Rubin этот показатель возрастает до 200 Тфлопс. При этом пиковая заявленная производительность векторных операций FP64 у Rubin составляет только 33 Тфлопс, то есть никакого улучшения по сравнению с Hopper не наблюдается.
Стоит отметить, что в AMD подвергли эту стратегию критике, указав, что она подходит не для всех сценариев использования и потому не готова к массовому внедрению. В то же время, эксперты предостерегают, что смещение акцента производителей в сторону выпуска чипов для ИИ-задач, оптимизированных под вычисления с пониженной точностью, может вызвать дефицит решений с полноценной поддержкой FP64 для HPC, что, в свою очередь, угрожает лидирующим позициям США на данном рыночном сегменте.
По мере того как NVIDIA наращивает возможности архитектуры Rubin для выполнения ИИ-задач с пониженной точностью вычислений, компания будет всё активнее использовать cuBLAS — библиотеку стандартных математических операций из стека CUDA-X, которая эмулирует вычисления с двойной точностью на тензорных ядрах, чтобы последовательно повышать показатели производительности FP64. «Мы стремимся предоставить эти инструменты сообществу разработчиков, чтобы они могли… достигать требуемой точности FP64», — заявил в декабрьском интервью HPCwire Дион Харрис (Dion Harris), старший директор NVIDIA по решениям для ИИ и HPC у крупнейших облачных провайдеров.
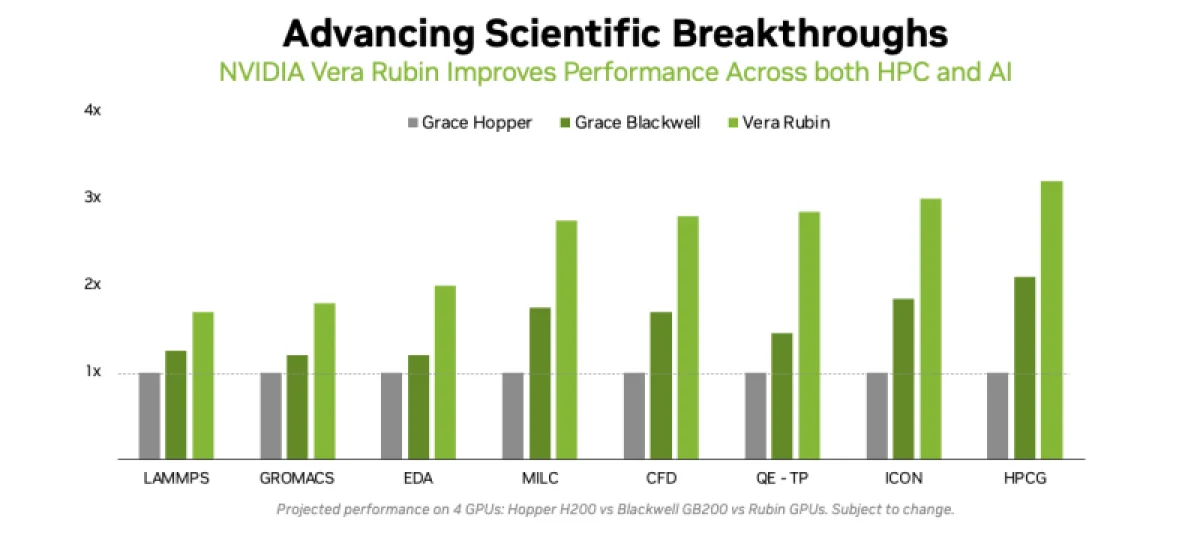
Производительность симуляции на GPU NVIDIA
Технологии NVIDIA для эмуляции базируются на схеме Озаки, которая даёт возможность проводить матричные умножения с повышенной точностью за счёт многократных операций пониженной точности на тензорных ядрах. В NVIDIA считают применение алгоритма Озаки обоснованным, так как наращивание производительности FP64 через увеличение числа CUDA-ядер не приведёт к реальному росту эффективности HPC-приложений, но снизит гибкость чипов. Как отмечает компания, изучение практических рабочих нагрузок демонстрирует, что «максимальная стабильная производительность FP64 чаще всего наблюдается именно при операциях умножения матриц». В архитектуре Hopper для этого существовали специализированные аппаратные модули, однако в Blackwell и Rubin NVIDIA в большей степени полагается на эмуляцию.
При этом производительность векторных вычислений FP64 сохраняет ключевое значение для научных задач, где матричные ядра не являются основными, признаёт NVIDIA, но сразу же добавляет, что в таких сценариях производительность упирается в скорость передачи данных через регистры, кэши и память HBM, а не в сами вычислительные ресурсы. Поэтому сбалансированная архитектура GPU «предоставляет ровно столько ресурсов FP64, сколько нужно для полной загрузки доступной пропускной способности памяти, избегая неэффективного выделения вычислительных мощностей». Другими словами, компания не планирует вносить коррективы.
Проект Genesis Mission, по всей видимости, будет разрабатывать разнообразные ИИ-приложения для научных и инженерных целей, и каждое из них, вероятно, будет предъявлять несколько отличающиеся требования к вычислениям. Нашли ли NVIDIA и AMD оптимальное соотношение, используя вычислительные ядра для матричных операций и полагаясь на эмуляцию по методу Озаки для FP64, ещё предстоит узнать, отмечает HPCwire.
Источник: