
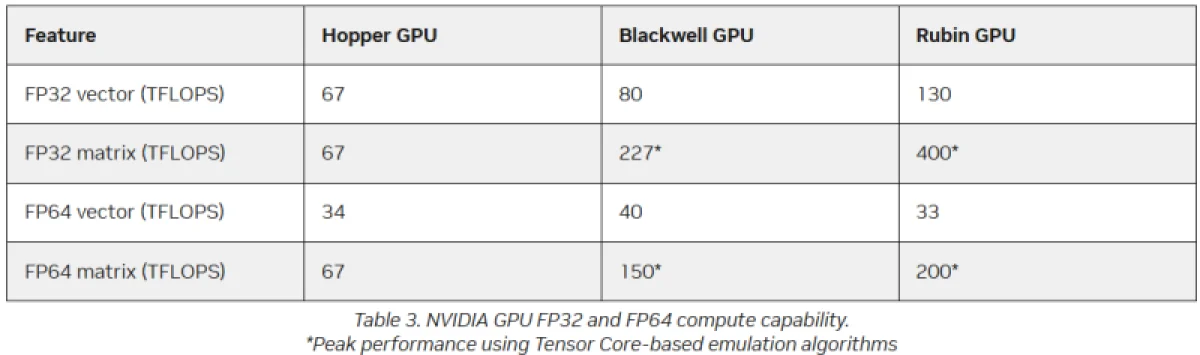
Вместо разработки специализированных процессоров для аппаратных вычислений с двойной точностью (FP64), NVIDIA применяет программную эмуляцию для повышения эффективности высокопроизводительных вычислений на своих ускорителях искусственного интеллекта, сообщает The Register. В архитектуре Blackwell Ultra компания не стала развивать блоки FP64, а в новейших чипах Rubin заявленная пиковая производительность векторных операций FP64 составляет 33 терафлопса. Для сравнения, у выпущенного четыре года назад ускорителя H100 этот показатель достигал 34 терафлопса, а у Blackwell — около 40 терафлопс.
Согласно заявлениям, при активации программной эмуляции в библиотеках CUDA от NVIDIA, ускоритель способен достичь производительности до 200 терафлопсов в матричных вычислениях FP64. При этом Blackwell с эмуляцией может выдать до 150 терафлопсов, тогда как у Hopper аппаратная производительность составляла 67 терафлопсов. «Многочисленные совместные исследования с партнёрами и наши внутренние изыскания показали, что точность, обеспечиваемая эмуляцией, как минимум сопоставима с точностью аппаратных тензорных ядер», — пояснил изданию The Register Дэн Эрнст (Dan Ernst), старший директор NVIDIA по продуктам для суперкомпьютеров.
Со своей стороны, в AMD полагают, что это утверждение верно не для всех рабочих задач. «В некоторых тестах она демонстрирует весьма хорошие результаты, однако в реальных научных симуляциях физических процессов это не столь очевидно», — отмечает Николас Малайя (Nicholas Malaya), научный сотрудник AMD. Он высказал мнение, что хотя эмуляция FP64, безусловно, заслуживает дальнейшего изучения и экспериментов, данное решение ещё не готово к повсеместному внедрению. AMD также исследует возможности программной эмуляции FP64 на своих ускорителях Instinct MI355X, чтобы определить потенциальные области её применения.
Источник изображения: Hilda Trinidad / Unsplash
Несмотря на растущую популярность форматов данных с пониженной точностью, FP64 по-прежнему считается эталоном для научных расчётов, и это оправдано — его динамический диапазон остаётся непревзойдённым. Современные большие языковые модели, однако, обучаются с применением вычислений FP8, а компактные типы MXFP8/MXFP4 или NVFP4 обеспечивают достаточный для задач ИИ спектр значений. Это эффективный подход для приблизительной математики LLM, но он не может заменить FP64 в высокопроизводительных вычислениях. ИИ-задачи демонстрируют высокую устойчивость к погрешностям, тогда как HPC-приложения требуют исключительной точности.
AMD обратила внимание на то, что эмуляция FP64 от NVIDIA не в полной мере соответствует стандарту IEEE. Реализованные NVIDIA алгоритмы не учитывают такие аспекты, как положительный и отрицательный ноль, а также особые состояния NaN (не число) и бесконечности. Как пояснил Малайя, из-за этого даже незначительные ошибки в промежуточных вычислениях, используемых для имитации повышенной точности, способны накапливаться и влиять на корректность итогового результата. По его мнению, целесообразность применения эмуляции FP64 сильно зависит от конкретной решаемой задачи.
Эмуляция FP64 наиболее эффективна для хорошо обусловленных задач, где малые изменения входных данных приводят к пропорционально малым изменениям в ответе. Классическим примером служит тест производительности Linpack (HPL). «Но если обратиться к областям вроде материаловедения, расчёта процессов горения или работы с ленточными матрицами, то мы имеем дело с гораздо хуже обусловленными системами, и здесь всё неожиданно начинает давать сбои», — отметил он.
Источник изображения: NVIDIA
Точность можно улучшить, наращивая число выполняемых операций, но за определённой границей эмуляция перестаёт давать выгоду. К тому же, все эти операции потребляют память. «Согласно имеющимся данным, для эмуляции матриц FP64 алгоритму Озаки необходимо примерно в два раза больше памяти», — пояснил Малайя. Поэтому фирма разрабатывает специализированные ускорители MI430X с увеличенной производительностью FP64/FP32, однако, как полагают исследователи, компания может не проявлять к ним активного интереса, поскольку ИИ-ускорители приносят более высокую прибыль.
По мнению Эрнста, для большинства специалистов в сфере HPC частичное несоответствие стандарту IEEE не является серьёзной трудностью. Многое определяется конкретным приложением. Тем не менее, NVIDIA создала дополнительные алгоритмы для выявления и снижения упомянутых погрешностей и неэффективности эмуляции. Эрнст также отметил, что использование памяти при эмуляции может быть несколько выше, но подчеркнул, что эти издержки касаются вычислений, а не самого приложения — в большинстве случаев речь идёт о матрицах размером в несколько гигабайт.
Однако это не отменяет того, что эмуляция применима лишь для части HPC-задач, основанных на операциях умножения плотных матриц (DGEMM). Как сообщил Малайя, для 60–70 % HPC-нагрузок эмуляция даёт несущественные преимущества или вообще не влияет на результат. «Согласно нашим оценкам, подавляющая часть реальных HPC-нагрузок использует векторное умножение (FMA), а не DGEMM», — сказал он, уточнив, что это действительно узкий сегмент, хотя и не мизерный. Для нагрузок с интенсивным использованием векторов, например, вычислительной гидродинамики (CFD), ускорители Rubin по-прежнему будут зависеть от медленных векторных FP64-блоков.
Источник: