
Google представила специализированные ускорители: TPU 8t для обучения моделей и TPU 8i для их запуска
Компания Google анонсировала два новых тензорных процессора восьмой серии: TPU 8t, предназначенный для обучения искусственного интеллекта, и TPU 8i, оптимизированный для выполнения ИИ-выводов. Хотя ранее компания уже тестировала разные версии своих чипов, например, модели пятого поколения V5p и V5e, более поздние разработки, такие как Trillium и Ironwood, в целом придерживались единой архитектурной концепции.
Как отметил Амин Вахдат (Amin Vahdat), старший вице-президент и главный технический специалист Google по ИИ и инфраструктуре, создание TPU 8t и TPU 8i стало итогом десятилетней работы (первые TPU были представлены в мае 2016 года). Эти процессоры разработаны специально для обеспечения высокой эффективности и масштабируемости суперкомпьютеров нового поколения. Вахдат охарактеризовал TPU 8t как «мощную платформу для обучения», которая позволяет «сократить цикл разработки моделей с нескольких месяцев до недель». По его словам, она обеспечивает в 2,8 раза более выгодное соотношение цены и производительности в сравнении с предшествующим поколением.
Источник изображений: Google
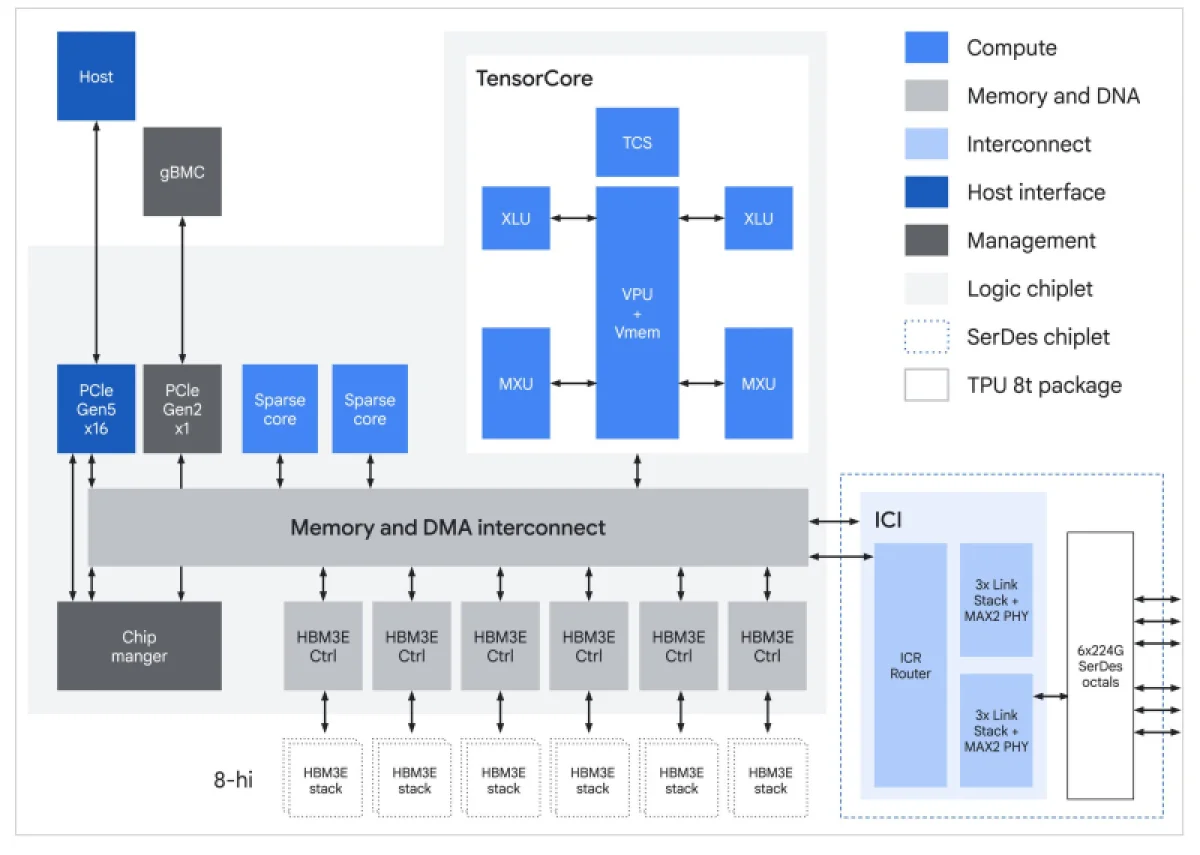
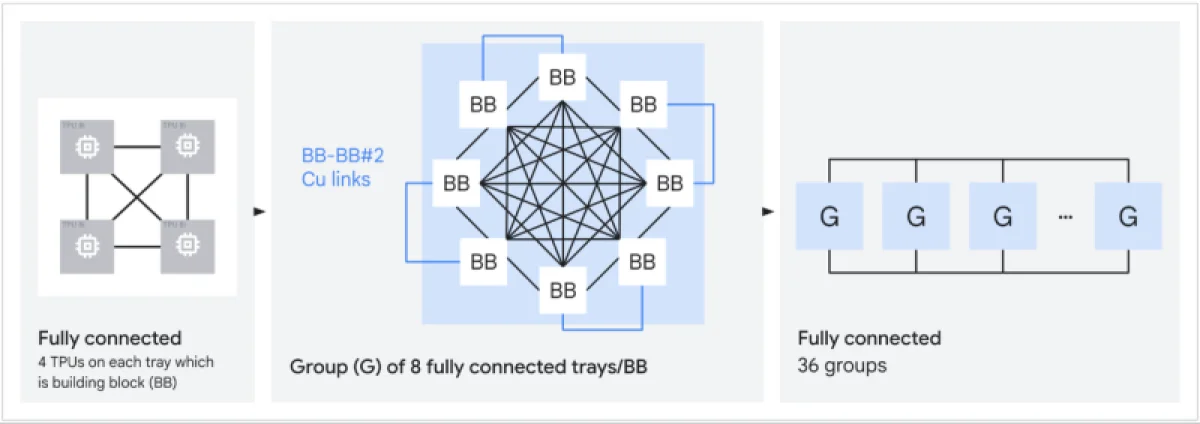
Архитектура TPU 8t включает векторные, матричные и SparseCore-ядра, а также оснащена 128 МБ статической памяти SRAM и 216 ГБ высокоскоростной памяти HBM с пропускной способностью 6,5 ТБ/с. Его производительность при работе с форматом FP4 достигает 12,6 петафлопс. Для вертикального масштабирования используется межчиповое соединение (ICI) со скоростью 19,2 Тбит/с в каждом направлении, а для горизонтального — канал 400 Гбит/с. Кластер на основе TPU 8t может объединять до 9,6 тысяч чипов, предоставляя 2 петабайта памяти HBM, вычислительную мощность 121 экзафлопс и вдвое более высокую межчиповую пропускную способность, чем у платформы Ironwood. Это позволяет самым сложным моделям работать с единым огромным пулом памяти.
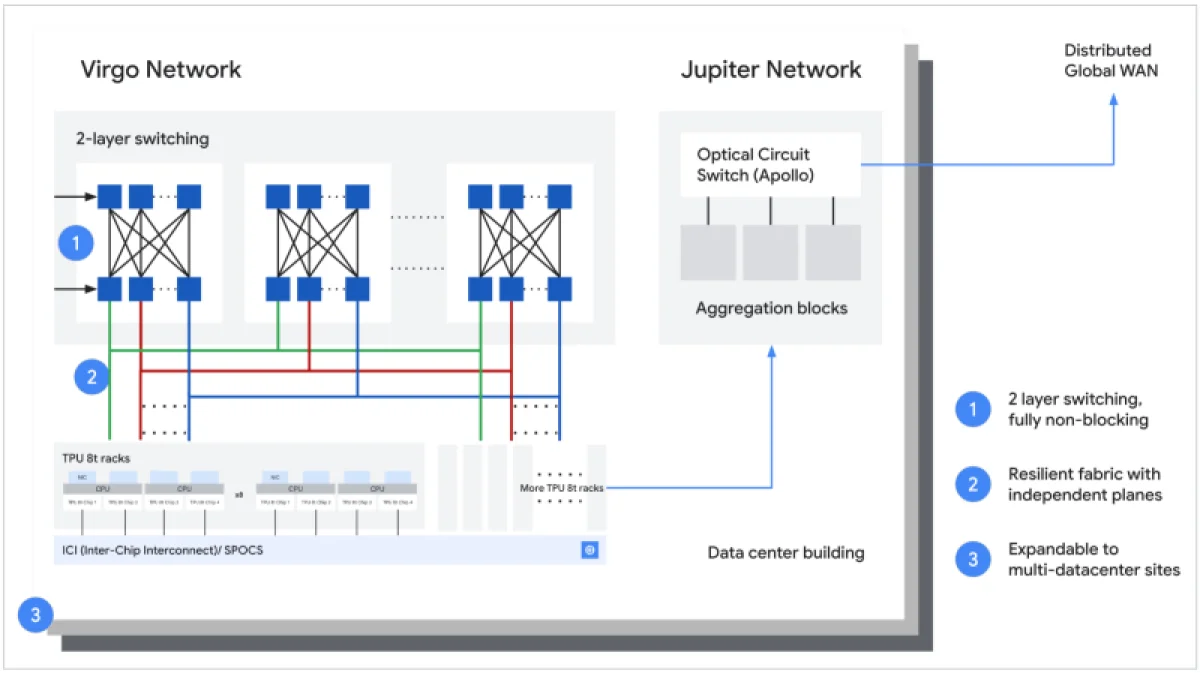
Кластеры на базе TPU 8t связывает сеть Virgo Network, построенная на плоской двухуровневой неблокирующей архитектуре. Она повышает пропускную способность в центре обработки данных в четыре раза, используя защищённые коммутаторы и сокращая число сетевых уровней. В пределах одного ЦОД Virgo Network поддерживает объединение до 134 тысяч чипов, обеспечивая до 47 Пбит/с неблокирующих соединений и свыше 1,6 эксафлопс производительности с практически линейным масштабированием. При объединении нескольких центров обработки данных в единый кластер можно задействовать более миллиона TPU.
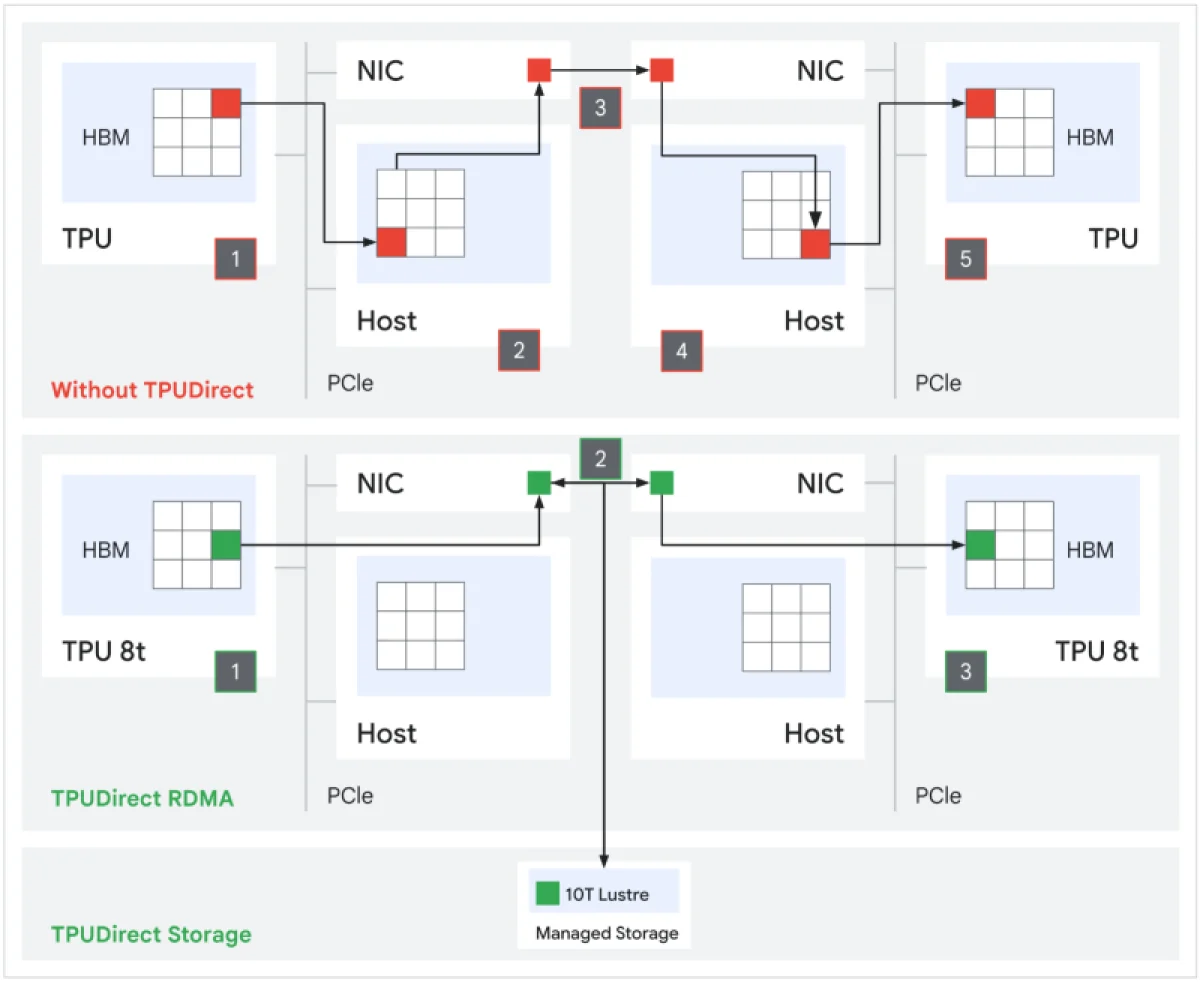
В TPU 8t применяются технологии TPUDirect RDMA и TPUDirect Storage. TPUDirect RDMA позволяет напрямую обмениваться данными между высокоскоростной памятью (HBM) и сетевым адаптером (NIC), минуя центральный процессор и оперативную память хоста. TPUDirect Storage устанавливает прямое соединение между памятью TPU и системами хранения, такими как Lustre на 10 Тбайт/с, что ускоряет доступ к хранилищу в десять раз по сравнению с решением Ironwood и обеспечивает доставку петабайтов данных к ускорителям.
Помимо этого, TPU 8t обладают расширенными функциями надёжности, доступности и обслуживания (RAS). Среди них — телеметрия в реальном времени для десятков тысяч чипов, автоматическое выявление неисправных каналов межчипового интерфейса (ICI) и перенаправление трафика без остановки задач, а также оптическая коммутация (OCS), которая автоматически переконфигурирует оборудование при сбоях. Эти механизмы позволяют достичь уровня использования чипов до 97 %.

TPU 8i разработан для выполнения сложных, совместных и итеративных задач, которые возникают при работе множества специализированных агентов в рамках развития агентного искусственного интеллекта. Этот чип оснащён 288 ГБ памяти HBM (с пропускной способностью 8,6 ТБ/с) и 384 МБ SRAM — это в три раза больше, чем у его предшественника. Как отмечает Google, такой объём SRAM позволяет TPU 8i хранить основную часть KV-кэша непосредственно на кристалле, что существенно сокращает простои вычислительных ядер при декодировании длинных последовательностей. Вместо SparseCores здесь применён новый встроенный ускоритель коллективных операций (CAE), который снижает задержки на уровне чипа и разгружает коммуникации между компонентами, предотвращая тем самым простой тензорных ядер, пишет The Register.
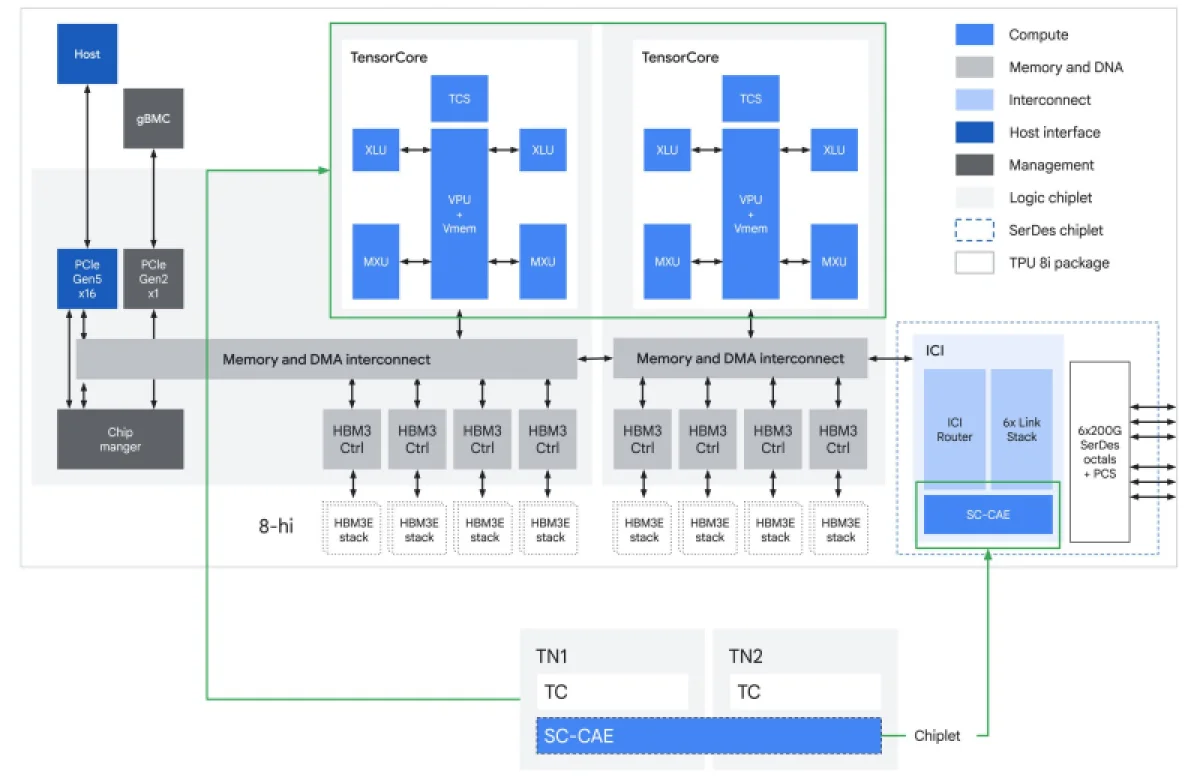
Масштабируемость TPU 8i достигает 1152 чипов в одном кластере (при этом одновременно активно до 1024), обеспечивая производительность 11,6 эксафлопс и 331,8 ТБ HBM. Межчиповый интерфейс ICI у модели 8i аналогичен TPU 8t, но для соединения чипов используется топология Boardfly вместо 3D-тора, поскольку для логического вывода на основе смеси экспертов (MoE) критически важно минимальное количество сетевых переходов. Благодаря этим усовершенствованиям, по заявлению компании, достигается на 80% более высокая производительность на доллар в сравнении с предыдущим поколением, что позволяет бизнесу обслуживать почти в два раза больше пользователей при неизменных затратах.
Как TPU 8t, так и 8i построены на собственных Arm-процессорах Axion и поддерживают систему жидкостного охлаждения. Google также сообщила об оптимизации общей эффективности системы, включая интегрированное управление питанием, способное динамически регулировать энергопотребление в реальном времени в зависимости от нагрузки. Это позволяет увеличить производительность на ватт до двух раз по сравнению с платформой Ironwood.

Фото: Sundar Pichai
Позже в текущем году Google Cloud Platform предоставит общий доступ к TPU 8. Они будут доступны как отдельные экземпляры, а также как компонент комплексной платформы AI Hypercomputer. Эта платформа интегрирует все необходимые сетевые ресурсы, системы хранения, вычислительные мощности и программное обеспечение для масштабного развертывания или обучения больших языковых моделей.
Источник информации: