В ходе нового этапа партнёрства с Intel компания SambaNova представила гетерогенную аппаратную платформу, интегрирующую графические процессоры, чипы Intel Xeon 6 и собственные RDU SambaNova для выполнения логического вывода в наиболее сложных агентных ИИ-приложениях. Полный ИИ-стек на базе этой разработки станет доступен во второй половине 2026 года. Партнёры также намерены запустить облачную платформу для искусственного интеллекта.
В этой архитектуре GPU берут на себя высокопараллельную стадию предварительного заполнения, эффективно преобразуя объёмные запросы в KV-кэши, тогда как RDU SambaNova отвечают за высокоскоростное декодирование с минимальной задержкой. Процессоры Xeon выступают в роли хост-процессоров, управляя системой, координируя задачи агентного ИИ, распределяя нагрузку, обрабатывая API-запросы и выполняя другие функции. На них также возложены компиляция и исполнение кода, а также проверка полученных результатов.
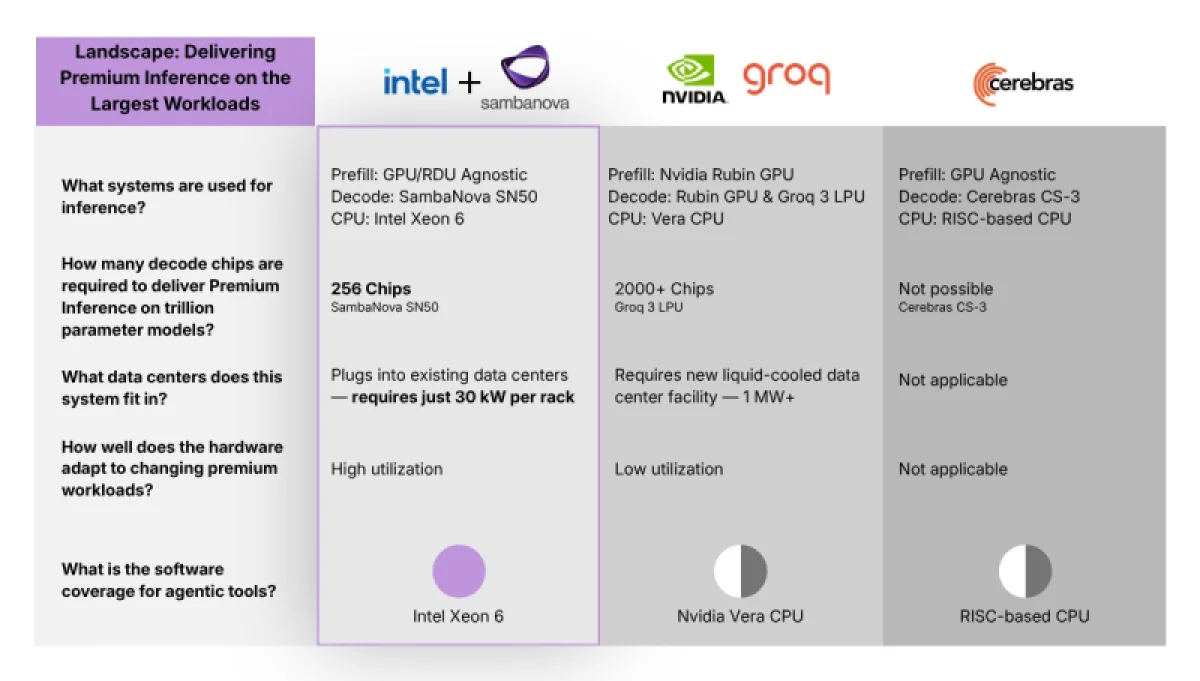
Источник изображений: Sambanova
Согласно данным измерений SambaNova, Xeon 6 демонстрирует более чем 50% преимущество в скорости компиляции LLVM по сравнению с серверными Arm-процессорами и до 70% более высокую производительность при работе с векторными базами данных в сравнении с существующими x86-решениями. Как отмечают компании, это ускоряет процесс создания ИИ-агентов, позволяя разработчикам быстрее воплощать идеи в работающие прототипы.

Как сообщило издание Data Center Dynamics, данное заявление последовало спустя месяц после анонса SambaNova чипа SN50 для агентных ИИ-нагрузок, который, по заявлению компании, в пять раз быстрее аналогов и в три раза эффективнее по совокупной стоимости владения. Тогда же было объявлено о «многолетнем стратегическом сотрудничестве» с Intel, нацеленном на создание «высокопроизводительных и экономичных решений для ИИ-инференса, предназначенных для разработчиков ИИ, провайдеров моделей, корпораций и государственных учреждений по всему миру».
Ранее компания Intel представила аналогичную гибридную архитектуру, основанную на своих ускорителях Habana Gaudi3 и решениях NVIDIA B200. Подобную стратегию распределения этапов инференса между различными чипами использует и NVIDIA в кластерах Vera Rubin, где применяются LPU от Groq (взамен Rubin CPX). Ключевое отличие подхода Intel в сотрудничестве с SambaNova от решения NVIDIA заключается в ориентации на «более защищённый» вариант, который не нуждается в сложной базовой инфраструктуре для распределённого инференса. Для клиентов, которые ищут модульное решение масштаба стойки, сфокусированное на разделении этапов «предварительного заполнения и декодирования», вариант от Intel и SambaNova может оказаться более предпочтительным.
Источник: