
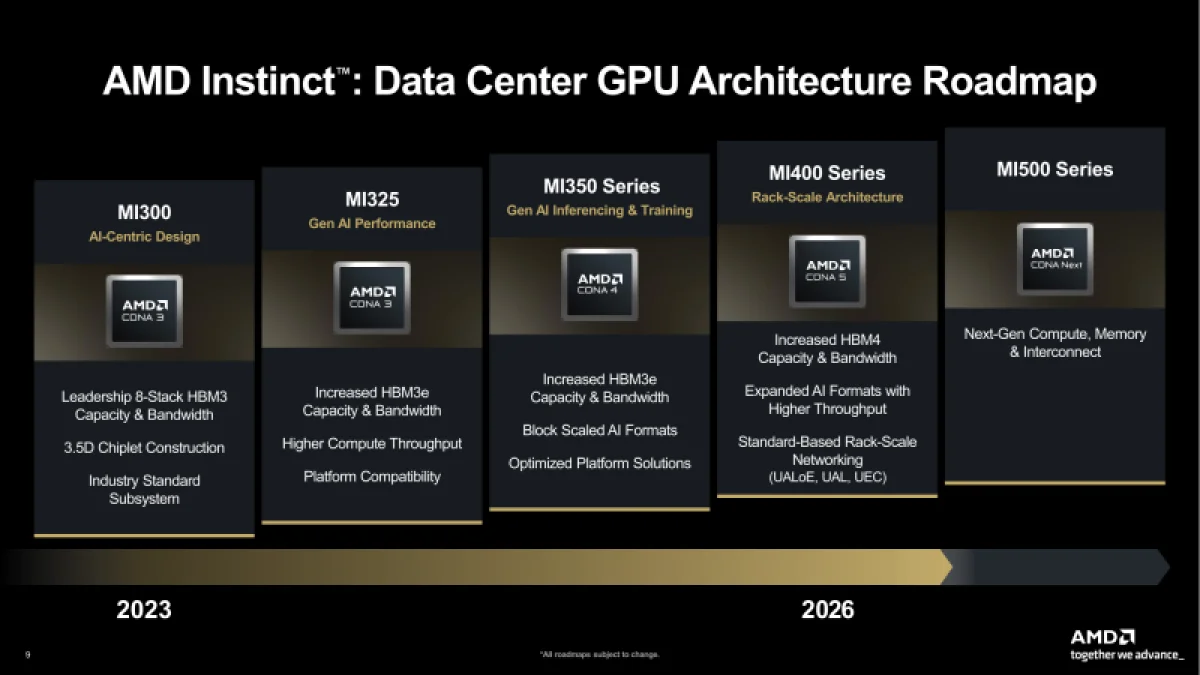
Изучив возможности эмуляции вычислений с двойной точностью (FP64) по методу Озаки, специалисты AMD пришли к выводу, что на данный момент невозможно обойтись без прямой, «аппаратной» производительности FP64. Как рассказал изданию HPCwire научный сотрудник компании Николас Малайя (Nicholas Malaya), для обеспечения необходимой точности в классических задачах моделирования и симуляции корпорация планирует значительно увеличить нативную производительность FP64 в ускорителе Instinct MI430X. Этот ускоритель ляжет в основу суперкомпьютера Discovery, запланированного к установке в Национальной лаборатории Ок-Ридж (ORNL) в 2028 году.
Как пояснили Кацухиса Озаки (Katsuhisa Ozaki) и двое его японских коллег, метод Озаки представляет собой перспективный новый подход к эмуляции, предназначенный для выполнения высокоточных операций с матрицами на оборудовании, поддерживающем форматы INT8/FP8, таком как современные ИИ-ускорители. Это достигается за счёт проведения множественных вычислений с пониженной точностью.
Малайя отметил, что существующие реализации Ozaki-I и Ozaki-II имеют ряд ограничений, препятствующих их практическому применению. Он выделил две ключевые сложности. Первая заключается в том, что программное обеспечение не соответствует стандарту IEEE и может давать результаты, отличные от выполнения того же кода на реальном оборудовании с поддержкой FP64. «В ряде случаев это приемлемо, — пояснил он, — но для многих распространённых типов матриц, которые мы изучали, погрешность оказывается весьма значительной.». Вторая проблема состоит в том, что схема Озаки оптимизирована для работы с квадратными матрицами. Если в вычислениях используются матрицы другой формы, итоговая производительность оказывается даже ниже, чем при прямом использовании FP64, добавил Малайя.
Источник изображения: AMD
Более того, высокопроизводительные вычисления (HPC) исторически ориентированы на векторные операции, в отличие от тензорных или матричных, типичных для задач искусственного интеллекта. Реальность ещё менее обнадёживающая — лишь менее 10% практических HPC-приложений адаптировали свои DGEMM-алгоритмы для извлечения выгоды из метода Озаки. «Насколько я знаю, ни Озаки-I, ни Озаки-II, ни какой-либо другой существующий подход не применим к векторным инструкциям, — отмечает Малайя. — Это принципиальный момент, который, по-моему, часто игнорируют». DGEMM действительно потребляет значительные вычислительные мощности, что делает схему Озаки применимой, «но она не охватывает 90% задач в области HPC».
AMD планирует реализовать программную эмуляцию метода Озаки в своих процессорах, заявил Малайя. «Нет никаких препятствий для этого. Это вопрос программного обеспечения. <…> Можно создать библиотеки, позволяющие гибко переключаться между аппаратными вычислениями и методом Озаки, а также, возможно, оценивать его эффективность», — пояснил он, добавив, что программная эмуляция может рассматриваться как запасной вариант для операций с двойной точностью (FP64). Однако, в конечном счёте, метод Озаки не представляет собой жизнеспособной альтернативы аппаратной реализации FP64, подчеркнул Малайя, отметив, что это мнение разделяют и другие эксперты.
Источник изображения: AMD
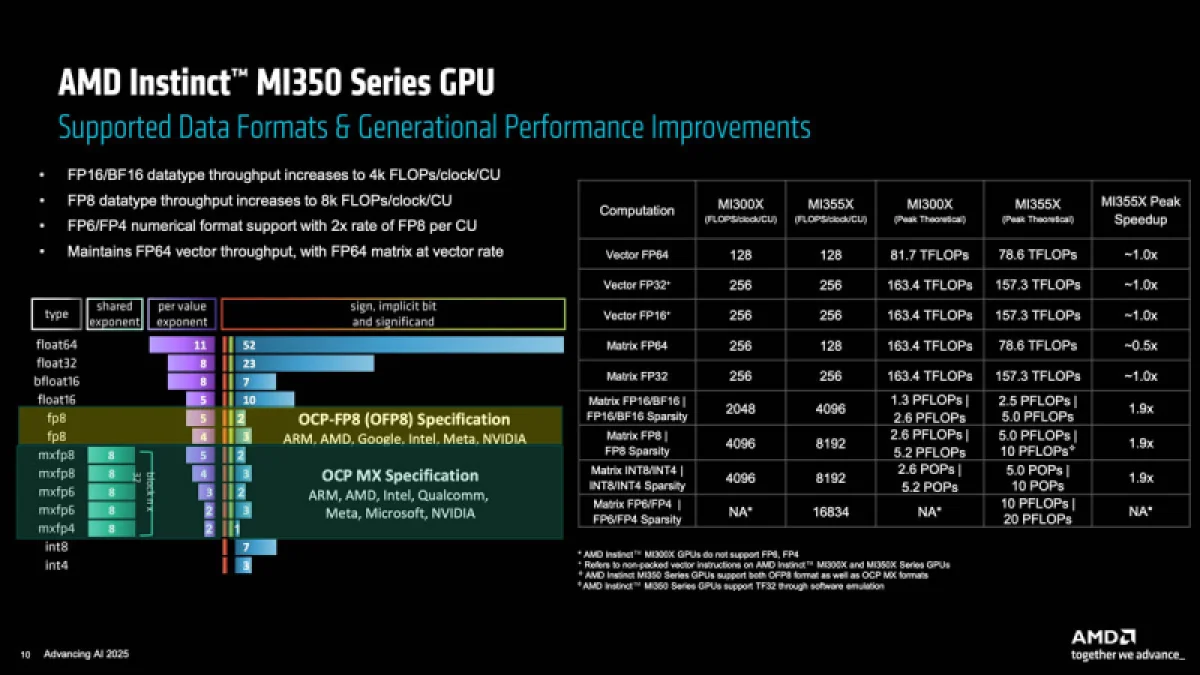
В данный момент компания работает над MI430X — специализированной модификацией ускорителя нового поколения MI450, которая будет обладать существенной производительностью в операциях FP64. Как сообщил Малайя, её показатель значительно превысит результат ускорителя MI355X, обеспечивающего 78,6 терафлопс. Для сравнения, предыдущая модель MI325X демонстрировала 81,7 терафлопс — в обоих случаях речь идёт о производительности как в векторных, так и в матричных вычислениях с двойной точностью.
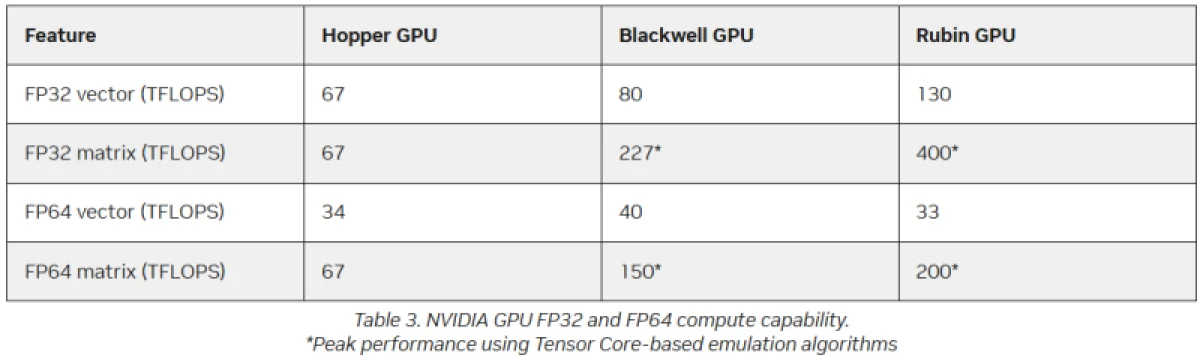
В любом случае, все эти чипы — от MI325 до MI430 — превосходят решения NVIDIA по производительности. И Hopper (34 терафлопс), и Blackwell (40 терафлопс) уже уступали в векторных FP64-операциях, однако у Hopper хотя бы были собственные 67 терафлопс в матричных расчётах, тогда как Blackwell в этой области уже перешёл на схему Озаки с «неаппаратными» 150 терафлопс. О Blackwell Ultra, где производительность FP64 снизилась до 1,3 терафлопс, NVIDIA в данном обсуждении предпочитает не упоминать, но обещает, что Rubin обеспечит 33 терафлопс в векторных FP64-вычислениях и 200 терафлопс в матричных (также с использованием метода Озаки).
Изображение предоставлено: NVIDIA
Компания NVIDIA объясняет своё решение не развивать аппаратные блоки FP64 тем, что простое наращивание вычислительной мощности для операций с двойной точностью не приведёт к реальному ускорению научных расчётов, поскольку на практике они будут ограничены пропускной способностью регистров, кэш-памяти и памяти HBM. Архитектура Rubin обеспечит пропускную способность HBM до 22 ТБ/с, что в 2,8 раза превышает показатель Blackwell. Как сообщил Малайя, модель Instinct MI325X предлагает 6 ТБ/с, MI355X — 8 ТБ/с, а у MI430X этот параметр достигнет уже 19,6 ТБ/с.
По мнению Малайи, наиболее эффективно синхронно инвестировать как в развитие HBM, так и в увеличение количества операций с плавающей запятой. «Ключевым параметром на самом деле является соотношение байт/флопс. Мы считаем, что необходимо придерживаться соотношения, гораздо более близкого к тому, что реализовано в современных решениях, — отметил он. — Чтобы сохранить так называемую арифметическую интенсивность на прежнем уровне, требуется существенно приблизиться к этому балансу при наращивании производительности FP64».
Изображение предоставлено: NVIDIA
Учитывая, что AMD планирует увеличить пропускную способность HBM в 2,5 раза при переходе от MI355 к MI430X, аналогичный рост производительности FP64 также выглядит логичным. Исходя из этого, можно приблизительно оценить, что MI430X сможет обеспечить производительность FP64 в диапазоне от 192 до 204 Тфлопс, в зависимости от того, какой чип взять за основу сравнения — более новый MI355 или более быстрый MI325, как сообщает HPCwire. При этом подчёркивается, что это лишь предположение, поскольку точные спецификации будущих чипов компания пока не раскрыла. Кроме того, остаётся не до конца ясным, будет ли производительность FP64 одинаковой для векторных и матричных вычислений.
Вычисления с двойной точностью «играют критически важную роль» для «Миссии Генезис» (Genesis Mission), как ранее заявил заместитель министра энергетики США по науке и инновациям Дарио Гил (Darío Gil). Он обратил внимание, что как глава AMD Лиза Су (Lisa Su), так и глава NVIDIA Дженсен Хуанг (Jensen Huang) подтвердили твёрдую приверженность поддержке формата FP64 в будущем. «FP64 крайне важен для задач моделирования и симуляции, не только для прогресса в традиционных научных изысканиях, но и для генерации данных, необходимых для обучения новых моделей искусственного интеллекта», — добавил Гил.
Изображение предоставлено: AMD
«Необходимо постоянно находить равновесие между объёмами вычислений в форматах FP64 и FP16», — пояснил Малайя. «В AMD уверены, что важно обеспечивать поддержку разнообразных типов данных в соответствии с запросами пользователей. Не может быть такого, чтобы всем и всегда было достаточно только FP64», — добавил он. По словам Малайи, здесь есть свои исключения. К примеру, ИИ-модели для предсказания структуры белков, такие как AlphaFold и Openfold, работают с FP32. Даже в классических областях высокопроизводительных вычислений, например в молекулярной динамике, зачастую не нужна точность FP64.
Однако, как отмечает исследователь, в настоящее время наблюдается существенный неудовлетворённый запрос на вычисления в формате FP64. «Мы полагаем, что в сфере HPC по-прежнему будет востребовано значительное количество операций с FP64, — заявил он. — Существуют алгоритмы, которые целиком ограничены пропускной способностью памяти и не требуют высокой вычислительной мощности. Но есть и другие — например, коды для расчётов в вычислительной химии и ряд иных задач, которые действительно обладают высокой арифметической интенсивностью и будут активно использовать FP64».
Источник информации: