
Amazon Web Services (AWS) и Cerebras Systems сообщили о партнёрстве, направленном на «создание в ближайшие месяцы наиболее производительных решений для задач вывода (инференса) в генеративном искусственном интеллекте и машинном обучении».
Эта технология, которая будет запущена на платформе Amazon Bedrock в дата-центрах AWS, интегрирует серверы на базе чипов AWS Trainium, системы Cerebras CS-3 с процессорами WSE-3 и сетевые адаптеры Amazon Elastic Fabric Adapter (EFA). Ожидается, что нововведение позволит ускорить генерацию ответов ИИ-моделями впятеро.
В AWS также заявили, что позднее в текущем году представят передовые решения с открытым исходным кодом для машинного обучения, а также собственные модели Amazon Nova, которые будут работать на оборудовании Cerebras.
Как подчеркнул Дэвид Браун (David Brown), вице-президент AWS по вычислительным и машинным сервисам, при выполнении инференса ключевым ограничением для ресурсоёмких задач, таких как помощь в программировании в реальном времени или интерактивные приложения, остаётся скорость: «Совместная разработка с Cerebras решает эту проблему: распределяя нагрузку по инференсу между Trainium и CS-3 и связывая их через адаптер Amazon Elastic Fabric, каждая система выполняет свою сильную сторону. В итоге процесс вывода станет на порядок быстрее и эффективнее современных аналогов».
Источник изображения: Amazon
Совместная платформа использует подход «разделения вывода» — метод, который делит процесс инференса ИИ на две фазы: этап интенсивной обработки промпта, или «префиллинга» (анализ запроса к языковой модели), и этап генерации ответа, известный как «декодирование», когда модель формирует итоговый результат для пользователя.
Префиллинг — это параллельный, требовательный к вычислениям процесс, не нуждающийся в высокой пропускной способности памяти. Декодирование же, напротив, является последовательной операцией с низкими вычислительными требованиями, но активно задействующей память. Как отметили в AWS, декодирование обычно занимает основную часть времени инференса, поскольку каждый выходной токен генерируется шаг за шагом.

Изображение предоставлено: Cerebras
Обычно функции предварительного заполнения и декодирования реализуются в рамках одного процессора. Однако в дезагрегированной системе AWS этап предзаполнения обеспечивается чипами Trainium, а за декодирование отвечает платформа Cerebras CS-3, построенная на основе WSE-3.
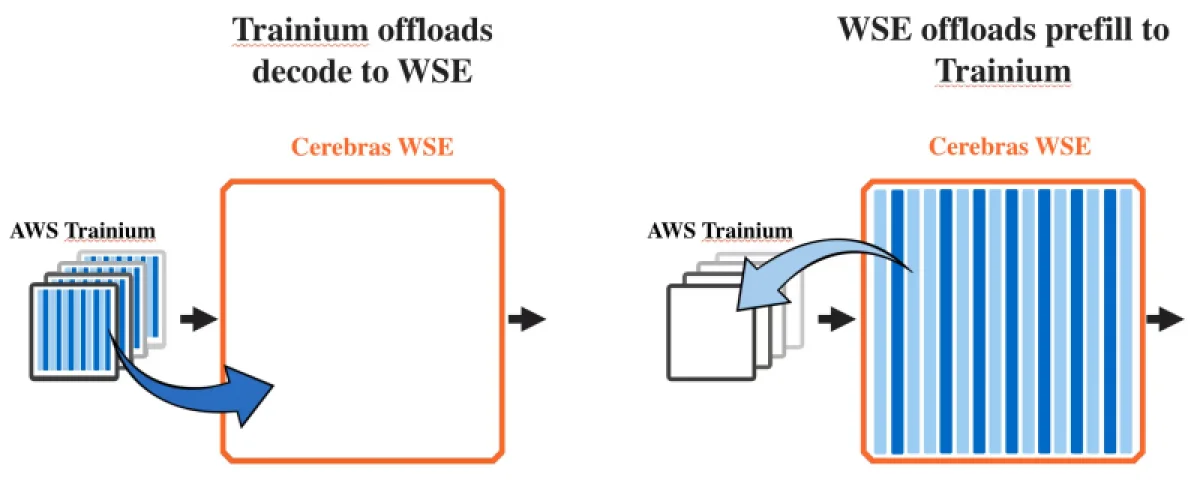
«Дезагрегированная архитектура оптимальна для масштабных и стабильных вычислительных задач, — отметил в корпоративном блоге директор по продуктовому маркетингу Cerebras Джеймс Ванг (James Wang). — При этом многие заказчики работают со смешанными нагрузками, где соотношение операций предзаполнения и декодирования варьируется; в таких случаях классический агрегированный подход остаётся предпочтительным. Мы полагаем, что большинству клиентов потребуется доступ к обоим типам решений».

Ключевое достоинство WSE-3 заключается в повышенной скорости обмена данными между логическими блоками и ячейками памяти по сравнению со многими аналогами. Согласно данным Cerebras, этот чип обеспечивает внутреннюю пропускную способность памяти на уровне 21 Пбайт/с, что существенно превосходит показатели межсоединения NVLink, используемого в ускорителях NVIDIA.
Недавно Cerebras заключила контракт с OpenAI на сумму 10 миллиардов долларов, предусматривающий поставку чипов общей энергоёмкостью 750 МВт до 2028 года. Это соглашение было анонсировано в промежутке между двумя раундами финансирования, которые в сумме принесли компании свыше 2 миллиардов долларов. Ожидается, что уже во втором квартале 2026 года Cerebras инициирует процедуру IPO. Как отмечает SiliconANGLE, партнёрства с AWS и OpenAI могут усилить интерес инвесторов к предстоящему выходу компании на биржу.
Оригинал публикации: